作业一:使用Scrapy爬虫框架,爬取网上信息并保存到文件中;分别读取爬取的数据创建ndarray、Series与DataFrame。 作业二:作业一结果的ndarray,进行数据的截取和排序操作。 作业三:作业一结果的Series,进行截取...
”c cra python python爬虫 scrapy 实战 爬虫 爬虫实战“ 的搜索结果
之前的一篇文章已经讲过怎样获取链接,怎样获得参数了,详情请看python爬取京东商城普通篇,本文将详细介绍利用python爬虫框架scrapy如何爬取京东商城,下面话不多说了,来看看详细的介绍吧。 代码详解 1、首先...
爬虫scrapy入门体验 安装scrapy pip install scrapy 如果需要安装C++,可以先下载安装twisted:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted(选择对应的python版本)。 创建项目 需要在项目根目录下,如D:\...

Scrapy是纯Python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便~ Scrapy 使用wisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种...
Scratch,是抓取的意思,这个Python的爬虫框架叫Scrapy,大概也是这个意思吧,就叫它:小刮刮吧。 小刮刮是一个为遍历爬行网站、分解获取数据而设计的应用程序框架,它可以应用在广泛领域:数据挖掘、信息处理和或者...
以前写过一篇文章《Python爬虫获取电子书资源实战》,以一个电子书的网站为例来实现python爬虫获取电子书资源。爬取整站的电子书资源,按目录保存到本地,并形成索引文件方便查找。这次介绍通过Scrapy爬虫框架来实现...
pythonscrapy爬虫实例Python爬虫Scrapy实例
py爬虫Python爬虫Scrapy培训源码提取方式是百度网盘分享地址
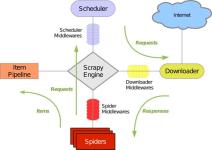
Scrapy的设计是用于Web爬虫,也可以用于提取数据和自动化测试。 Scrapy提供了一个内置的HTTP请求处理器,可以通过编写自定义的中间件来扩展其功能。Scrapy使用Twisted事件驱动框架,可以同时处理数千个并发请求。 ...
Python爬虫之Scrapy框架系列(23)——分布式爬虫scrapy_redis浅实战【XXTop250部分爬取】

新建项目(命令行:scrapy startproject xxx):新建一个爬虫项目 明确目标(编写items.py):明确你想要抓取的目标 制作爬虫(spiders/xxspider.py):制作爬虫开始爬取网页 存储内容(pipelines.py):设计管道...
【Python高级开发课程 高级教程】课程列表01 Python语言开发要点详解.pptx02 Python数据结构.pptx03 Python函数和函数式编程....多进程开发.pptx09 Python爬虫框架Scrapy实战.pptx10 Python Web开发框架Django实战.pptx
基础的框架,适合入门选手
Python 爬虫Scrapy课件源码 Scrapy安装所需要的软件 爬虫代码实例源码大全(纯源码不带视频的实例) 轻量级爬虫
Python 爬虫Scrapy课件源码

爬虫scrapy框架小实例,在dos窗口项目所在目录,使用scrapy crawl basic 直接爬取,显示内容和网站的内容一样。

不会的同学可参考我的另一篇博文,这里不再赘述:Python之Scrapy爬虫实战–新建scrapy项目 这里只讲一下几个关键点,完整代码在文末。 由于爬取的网站有反爬,一开始没绕过反爬,debug几下代码就被封了ip(我只是在...
python爬虫 python爬虫_爬虫项目实战之Scrapy抓手机今日头条App数据并存入MongoDB
精通Python爬虫框架Scrapy.pdf
创建爬虫 cd zhaoping scrapy genspider hr zhaopingwang.com 目录结构 items.py title = scrapy.Field() position = scrapy.Field() publish_date = scrapy.Field() pipelines.py from pymongo import ...
Python-Scrapy 入门级爬虫项目实战 糗事百科段子爬取
推荐文章
- 机器学习算法之K-means(K均值聚类)算法_k-means聚类算法的anchors_num的最大值-程序员宅基地
- edu教育邮箱免费申请注册Google drive无限网盘和微软OneDrive经验分享_onedrive a5-程序员宅基地
- 把平板、手机作为电脑第二屏幕(Linux系统下)_平板副屏linux-程序员宅基地
- JPA 批注参考(3)-程序员宅基地
- 小白也能搞定!Windows10上CUDA9.0+CUDNN7.0.5的完美安装教程-程序员宅基地
- Ubuntu 16.04安装后的简单配置和常用软件安装-程序员宅基地
- Pillow的使用-Image篇_pillow image-程序员宅基地
- jquery 基础掌握_jquery掌握-程序员宅基地
- linux服务器时间同步_linux修改同步时间服务器地址和频率-程序员宅基地
- 使用MPU6050 DIY Arduino倾角仪_diy倾角仪-程序员宅基地